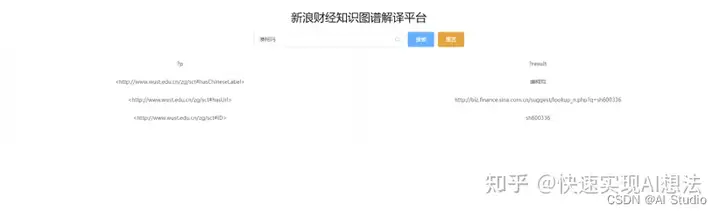
新浪财经知识图谱解译平台
经济就是人们生产、流通、分配、消费一切物质精神资料的总称。经济的发展与人民生活息息相关。
新浪财经是国内第一大财经网络媒体。新浪财经打造高端新闻资讯,深度挖掘业内信息,全程报道80%以上的业界重要会议及事件,独家率达90%,是最具影响力的主流媒体平台。同时,新浪财经也开发出如金融超市、股市行情、基金筛选器、呼叫中心,金融产物在线查询等一系列实用产物,资助网民理财,是最为贴心实用的服务平台。除此之外,新浪财经为网友搭建互动、交流、学习的财经大平台。财经博客、财经吧、模拟股市、模拟汇市等均成为业界最早、人气最旺、最知名的财经互动社区。
基于领先的财经资讯和贴心的产物服务,新浪财经吸引了非常庞大的高端用户群,已经成为金融行业客户进行网络营销的主要平台,同时也获得了非金融类客户的广泛青睐。
本项目爬取新浪财经中的股票信息,制作成知识图谱,并实验对知识图谱进行解译。
项目设计
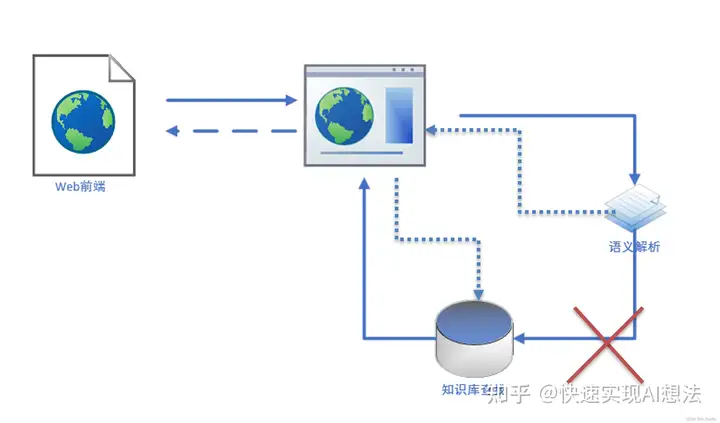
项目设计如图,web前端接收用户输入,将用户输入发送到后台的用户服务器,并由用户服务器转发到语义解析服务,语义解析根据用户输入信息转化为sparql语言,发送给用户服务器,用户服务器再将sparql发送到知识图谱库中查找结果返回给用户服务器,最终用户服务器将结果显示到前端。
数据获取以及构建知识图谱
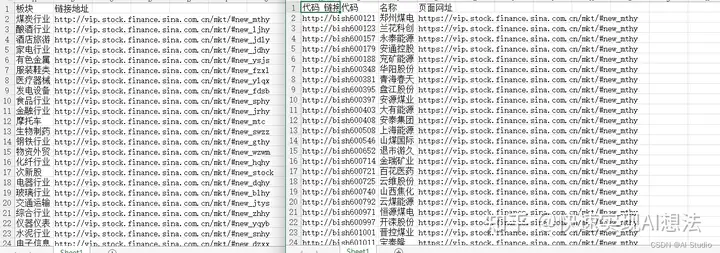
使用软件对新浪财经网站进行爬取,爬取后的数据
生存为Excel文件。
使用python读取Excel并
根据数据格式自定义三元组,将三元组
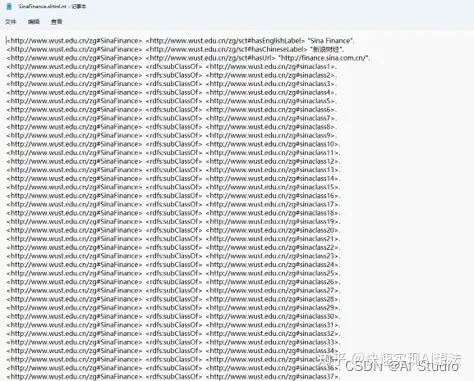
生存为.shtml.nt文件,代码如下。
在GraphDB上新开一个知识库,将.shtml.nt文件导入到知识库中
import pandas as pd
import numpy as np
df = pd.read_excel(新浪行业_板块行情_新浪财经_新浪网.xlsx)
with open(SinaFinance.shtml.nt,w,encoding=utf-8) as fp:
fp.write(<http://www.wust.edu.cn/zg#SinaFinance> <http://www.wust.edu.cn/zg/sct#hasEnglishLabel> "Sina Finance".\n)
fp.write(<http://www.wust.edu.cn/zg#SinaFinance> <http://www.wust.edu.cn/zg/sct#hasChineseLabel> "新浪财经".\n)
fp.write(<http://www.wust.edu.cn/zg#SinaFinance> <http://www.wust.edu.cn/zg/sct#hasUrl> "http://finance.sina.com.cn/".\n)
classes = np.array(df[板块]).astype(np.str)
for i,v in enumerate(classes):
fp.write(<http://www.wust.edu.cn/zg#SinaFinance> <rdfs:subClassOf> <http://www.wust.edu.cn/zg#sinaclass+str(i+1)+>.\n)
import pandas as pd
import numpy as np
df = pd.read_excel(新浪行业_板块行情_新浪财经_新浪网.xlsx)
df2 = pd.read_excel(行情中心_新浪财经_新浪网.xlsx)
with open(SinaClass.shtml.nt,w,encoding=utf-8) as fp:
classes = np.array(df[板块]).astype(np.str)
for i,v in enumerate(classes):
fp.write(<http://www.wust.edu.cn/zg#sinaclass+str(i+1)+> <http://www.wust.edu.cn/zg/sct#hasChineseLabel> "+v+".\n)
classes = np.array(df[链接地址]).astype(np.str)
for i,v in enumerate(classes):
fp.write(<http://www.wust.edu.cn/zg#sinaclass+str(i+1)+> <http://www.wust.edu.cn/zg/sct#hasUrl> "+v+".\n)
id = np.array(df2[页面网址]).astype(np.str)
id2 = np.array(df[链接地址]).astype(np.str)
for i,v in enumerate(id):
for j,k in enumerate(id2):
if v.split(#)[-1]==str(k).split(#)[-1] and not pd.isnull(df2.loc[i,代码]):
fp.write(<http://www.wust.edu.cn/zg#sinaclass+str(j+1)+> <rdfs:subClassOf> <http://www.wust.edu.cn/zg/stockID#+str(df2.loc[i,代码])+>.\n)
with open(Stock.shtml.nt,w,encoding=utf-8) as fp:
id = np.array(df2[代码]).astype(np.str)
for i,v in enumerate(id):
fp.write(<http://www.wust.edu.cn/zg/stockID#+str(v)+> <http://www.wust.edu.cn/zg/sct#ID> "+str(v)+".\n)
fp.write(<http://www.wust.edu.cn/zg/stockID#+str(v)+> <http://www.wust.edu.cn/zg/sct#hasChineseLabel> "+str(df2.loc[i,名称])+".\n)
fp.write(<http://www.wust.edu.cn/zg/stockID#+str(v)+> <http://www.wust.edu.cn/zg/sct#hasUrl> "+str(df2.loc[i,代码_链接])+".\n)
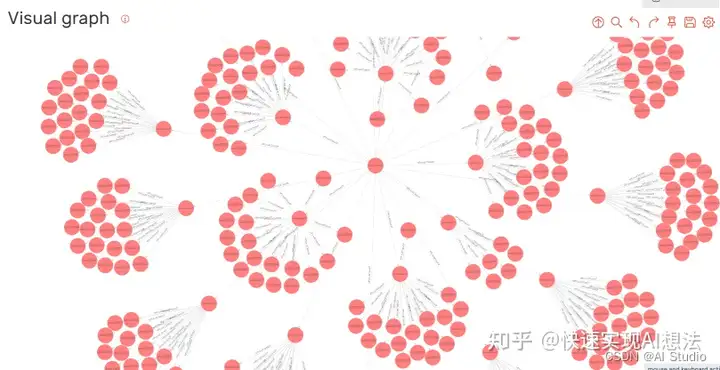
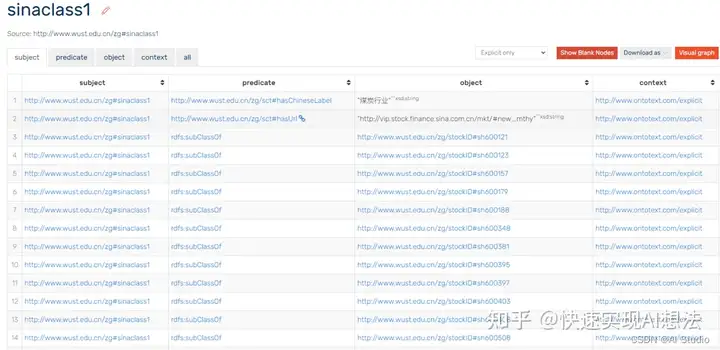
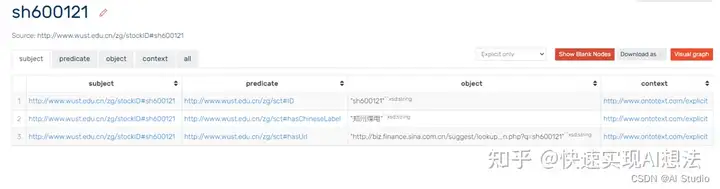
知识图谱结构展示
web前后端设计
前端
前端使用vue框架进行设计,代码详见SinaFinanceKnowledge\zg-vue
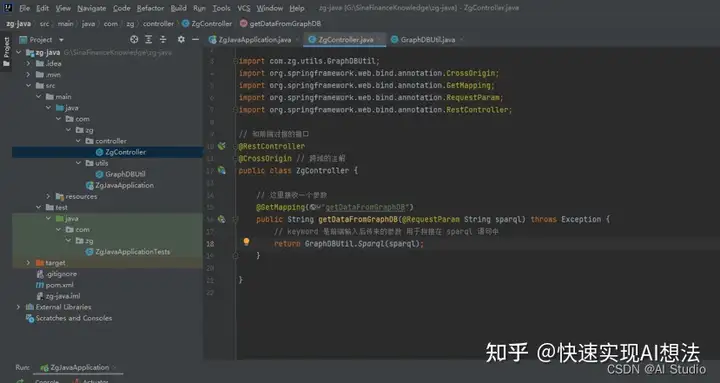
用户服务器
后台使用springboot撰写与知识图谱的对接接口,代码详见SinaFinanceKnowledge\zg-java
语义解析服务器
由于语义解析部门使用python+paddlepaddle构建,所以语义解析服务器使用django搭建的,代码详见SinaFinanceKnowledge\text2sparql
语义解析
代码及模型
详见text2sparql.ipynb
摆设
由于深度学习使用的python语言,所以当地摆设使用django第三方库来生成后台服务接口。摆设代码和预测代码差不多。 这里注意的是,由于我们生成的辞书全部使用小写,所以生成后的部门语句中的特定词需要转为sparql中的定义词。如:
sparql = " ".join(word_list_s).replace(sct:haschineselabel,sct:hasChineseLabel).replace(sct:id,sct:ID).replace(zg:sinafinance,zg:SinaFinance)
总结与展望
目前仅使用了seq2seq,即自然语言生成的方式来完成text2sparql,效果看起来还不错,但仍有不敷。
到场深度学习的数据集较少,在少量的数据集上,精度也不能完全拟合。
部门词语如:煤炭行业、“煤炭行业”,其实是一样的,但仍然在token映射时,映射为
差别的词向量,后续可以改进。
后期可以扩大数据集,调整模型结构,或者使用信息抽取以及归类、匹配的方式构造sparql。
项目开源
Github传送门:https://github.com/Shelly111111/SinaFinanceKnowledge
AI Studio传送门:https://aistudio.baidu.com/aistudio/projectdetail/4247914